**CN coins:** The last test of your fork is to make sure your new difficulties …when you sync from 0 are matching the old difficulties when running the pre-fork code. **[See this note.](https://github.com/zawy12/difficulty-algorithms/issues/32)**
FWIW, it's possible to do the LWMA without looping over N blocks, using only the first and last difficulties (or targets) and their timestamps. In terms of difficulty, I believe it's:
```
ts = timestamp D_N is difficulty of most recently solved block.
D_{N+1} = next_D
S is the previous denominator:
S = D_N / [ D_{N-2} + D_{N-1}/N - D_{-1}/N ] * k * T
k = N/2*(N+1)
D_{N+1} = [ D_{N-1} + D_N/N - D_0/N ] * T * k /
[ S - (ts_{N-1}-ts_0) + (ts_N-ts_{N-1})*N ]
```
I discovered a security weakness on 5/16/2019 due to my past FTL recommendations (which prevent bad timestamps from lowering difficulty). This weakness aka exploit does not seem to apply to Monero and Cryptonote coins that use node time instead of network time. If your coin uses network time instead of node local time, lowering FTL < about 125% of the "revert to node time" rule (70 minutes in BCH, ZEC, & BTC) will allow a 33% Sybil attack on your nodes, so the revert rule must be ~ FTL/2 instead of 70 minutes. If your coin uses network time without a revert rule (a bad design), it is subject to this attack under all conditions See: [https://github.com/zcash/zcash/issues/4021](https://github.com/zcash/zcash/issues/4021)
People like reading the **[history of this algorithm.](https://github.com/zawy12/difficulty-algorithms/issues/24)**
**Comparing algorithms on live coins: [Difficulty Watch](http://wordsgalore.com/diff/index.html)**
[Send me](mailto:[email protected]) a link to open daemon or full API to be included.
### LWMA for Bitcoin & Zcash Clones
See **[LWMA code for BTC/Zcash clones](https://github.com/zawy12/difficulty-algorithms/issues/3#issuecomment-442129791)** in the comments below. Known BTC Clones using LWMA: are BTC Gold, BTC Candy, Ignition, Pigeon, Zelcash, Zencash, BitcoinZ, Xchange, Microbitcoin.
**Testnet Checking**
**[Emai me](mailto:[email protected])** a link to your code and then send me 200 testnet timestamps and difficulties (CSV height, timestamp, difficulty). To fully test it, you can send out-of-sequence timestamps to testnet by changing the clock on your node that sends your miner the block templates. There's a Perl script in my github code that you can use to simulate hash attacks on a single-computer testnet. Here's example code for getting the CSV timestamps/difficulty data to send me:
```
curl -X POST http://127.0.0.1:38782/json_rpc -d '{"jsonrpc":"2.0","id":"0","method":"getblockheadersrange","params":{"start_height":300,"end_height":412}}' -H 'Content-Type: application/json' | jq -r '.result.headers[] | [.height, .timestamp, .difficulty] | @csv'
```
**Discord**
There is a discord channel for devs using this algorithm. You must have a coin and history as a dev on that coin to join. Please email me at [email protected] to get an invite.
**Donations**
Thanks to Sumo, Masari, Karbo, Electroneum, Lethean, and XChange.
38skLKHjPrPQWF9Vu7F8vdcBMYrpTg5vfM or your coin if it's on TO or cryptopia.
**LWMA Description**
This sets difficulty by estimating current hashrate by the most recent difficulties and solvetimes. It divides the average difficulty by the Linearly Weighted Moving Average (LWMA) of the solvetimes. This gives it more weight to the more recent solvetimes. It is designed for small coin protection against timestamp manipulation and hash attacks. The basic equation is:
```next_difficulty = average(Difficulties) * target_solvetime / LWMA(solvetimes)```
LWMA-2/3/4 are now not recommended because I could not show they were better than LWMA-1.
<!--
**LWMA-2** is LWMA with 8% jump when last 3 solvetimes were < 0.8xT. Finished Aug 2018.
**LWMA-3** fixes an exploit that enabled s>50% miners to do block withholding to get unlimited blocks.Finished Oct 2018.
**LWMA-4** (Nov 2018)
1. Limited LWMA-2's jumps to 5% above avg D.
2. Added 1 & 2 block triggers to LWMA-2's 3-block trigger to start jumping 10% per block.
3. Drops slower if there are fast solvetimes followed by a really long solvetime (a NH problem).
4. Converts difficulty to easier-to-read number by converting 123,456,789 to 12300000.
5. Makes least 2 digits of difficulty equal the estimated hashrate of the last 11 blocks. 123000053 means the last 11 blocks have a hashrate 5.3x higher than the difficulty expected.
**LWMA-4 is LWMA if all the options are removed.** (And convert the 97 to 99.)
-->
### LWMA-1
Use this if you do not have NiceHash etc problems.
See LWMA-4 below for more aggressive rules to help prevent NiceHash delays,
```
// LWMA-1 difficulty algorithm
// Copyright (c) 2017-2018 Zawy, MIT License
// See commented link below for required config file changes. Fix FTL and MTP.
// https://github.com/zawy12/difficulty-algorithms/issues/3
// The following comments can be deleted.
// Bitcoin clones must lower their FTL. See Bitcoin/Zcash code on the page above.
// Cryptonote et al coins must make the following changes:
// BLOCKCHAIN_TIMESTAMP_CHECK_WINDOW = 11; // aka "MTP"
// DIFFICULTY_WINDOW = 60; // N=60, 90, and 150 for T=600, 120, 60.
// BLOCK_FUTURE_TIME_LIMIT = DIFFICULTY_WINDOW * DIFFICULTY_TARGET / 20;
// Warning Bytecoin/Karbo clones may not have the following, so check TS & CD vectors size=N+1
// DIFFICULTY_BLOCKS_COUNT = DIFFICULTY_WINDOW+1;
// The BLOCKS_COUNT is to make timestamps & cumulative_difficulty vectors size N+1
// If your coin uses network time instead of node local time, lowering FTL < about 125% of
// the "revert to node time" rule (70 minutes in BCH, ZEC, & BTC) will allow a 33% Sybil attack
// on your nodes. So revert rule must be ~ FTL/2 instead of 70 minutes. See:
// https://github.com/zcash/zcash/issues/4021
difficulty_type LWMA1_(std::vector<uint64_t> timestamps,
std::vector<uint64_t> cumulative_difficulties, uint64_t T, uint64_t N, uint64_t height,
uint64_t FORK_HEIGHT, uint64_t difficulty_guess) {
// This old way was not very proper
// uint64_t T = DIFFICULTY_TARGET;
// uint64_t N = DIFFICULTY_WINDOW; // N=60, 90, and 150 for T=600, 120, 60.
// Genesis should be the only time sizes are < N+1.
assert(timestamps.size() == cumulative_difficulties.size() && timestamps.size() <= N+1 );
// Hard code D if there are not at least N+1 BLOCKS after fork (or genesis)
// This helps a lot in preventing a very common problem in CN forks from conflicting difficulties.
if (height >= FORK_HEIGHT && height < FORK_HEIGHT + N) { return difficulty_guess; }
assert(timestamps.size() == N+1);
uint64_t L(0), next_D, i, this_timestamp(0), previous_timestamp(0), avg_D;
previous_timestamp = timestamps[0]-T;
for ( i = 1; i <= N; i++) {
// Safely prevent out-of-sequence timestamps
if ( timestamps[i] > previous_timestamp ) { this_timestamp = timestamps[i]; }
else { this_timestamp = previous_timestamp+1; }
L += i*std::min(6*T ,this_timestamp - previous_timestamp);
previous_timestamp = this_timestamp;
}
if (L < N*N*T/20 ) { L = N*N*T/20; }
avg_D = ( cumulative_difficulties[N] - cumulative_difficulties[0] )/ N;
// Prevent round off error for small D and overflow for large D.
if (avg_D > 2000000*N*N*T) {
next_D = (avg_D/(200*L))*(N*(N+1)*T*99);
}
else { next_D = (avg_D*N*(N+1)*T*99)/(200*L); }
// Optional. Make all insignificant digits zero for easy reading.
i = 1000000000;
while (i > 1) {
if ( next_D > i*100 ) { next_D = ((next_D+i/2)/i)*i; break; }
else { i /= 10; }
}
return next_D;
}
```
The following is an idea that could be inserted right before "return next_D;
```
// Optional.
// Make least 2 digits = size of hash rate change last 11 BLOCKS if it's statistically significant.
// D=2540035 => hash rate 3.5x higher than D expected. Blocks coming 3.5x too fast.
if ( next_D > 10000 ) {
uint64_t est_HR = (10*(11*T+(timestamps[N]-timestamps[N-11])/2)) /
(timestamps[N]-timestamps[N-11]+1);
if ( est_HR > 5 && est_HR < 25 ) { est_HR=0; }
est_HR = std::min(static_cast<uint64_t>(99), est_HR);
next_D = ((next_D+50)/100)*100 + est_HR;
}
```
<!--
### Do not use LWMA-4 if you are a CN/Monero/Bytecoin/Forknote coin unless your pools are adjusting the timestamps during hashing. If your pools have not fixed this error, LWMA-4 will make their results worse and cause more delays in your coin, giving Nicehash an advantage over your pools.
### LWMA-4 for CN / Monero coins
For dealing with NiceHash or other extensive on-off mining problems.
```
// LWMA-4 difficulty algorithm
// Copyright (c) 2017-2018 Zawy, MIT License
// https://github.com/zawy12/difficulty-algorithms/issues/3
// See commented version for explanations & required config file changes. Fix FTL and MTP!
difficulty_type next_difficulty_v3(std::vector<uint64_t> timestamps,
std::vector<difficulty_type> cumulative_difficulties) {
uint64_t T = DIFFICULTY_TARGET_V2;
uint64_t N = DIFFICULTY_WINDOW_V2; // N=45, 60, and 90 for T=600, 120, 60.
uint64_t L(0), ST(0), next_D, prev_D, avg_D, i;
assert(timestamps.size() == cumulative_difficulties.size() && timestamps.size() <= N+1 );
// If it's a new coin, do startup code. Do not remove in case other coins copy your code.
uint64_t difficulty_guess = 100;
if (timestamps.size() <= 12 ) { return difficulty_guess; }
if ( timestamps.size() < N +1 ) { N = timestamps.size()-1; }
// If hashrate/difficulty ratio after a fork is < 1/3 prior ratio, hardcode D for N+1 blocks after fork.
// This will also cover up a very common type of backwards-incompatible fork.
// difficulty_guess = 100000; // Dev may change. Guess low than anything expected.
// if ( height <= UPGRADE_HEIGHT + 1 + N ) { return difficulty_guess; }
// Safely convert out-of-sequence timestamps into > 0 solvetimes.
std::vector<uint64_t>TS(N+1);
TS[0] = timestamps[0];
for ( i = 1; i <= N; i++) {
if ( timestamps[i] > TS[i-1] ) { TS[i] = timestamps[i]; }
else { TS[i] = TS[i-1]; }
}
for ( i = 1; i <= N; i++) {
// Temper long solvetime drops if they were preceded by 3 or 6 fast solves.
if ( i > 4 && TS[i]-TS[i-1] > 5*T && TS[i-1] - TS[i-4] < (14*T)/10 ) { ST = 2*T; }
else if ( i > 7 && TS[i]-TS[i-1] > 5*T && TS[i-1] - TS[i-7] < 4*T ) { ST = 2*T; }
else { // Assume normal conditions, so get ST.
// LWMA drops too much from long ST, so limit drops with a 5*T limit
ST = std::min(5*T ,TS[i] - TS[i-1]);
}
L += ST * i ;
}
if (L < N*N*T/20 ) { L = N*N*T/20; }
avg_D = ( cumulative_difficulties[N] - cumulative_difficulties[0] )/ N;
// Prevent round off error for small D and overflow for large D.
if (avg_D > 2000000*N*N*T) {
next_D = (avg_D/(200*L))*(N*(N+1)*T*97);
}
else { next_D = (avg_D*N*(N+1)*T*97)/(200*L); }
prev_D = cumulative_difficulties[N] - cumulative_difficulties[N-1] ;
// Apply 10% jump rule.
if ( ( TS[N] - TS[N-1] < (2*T)/10 ) ||
( TS[N] - TS[N-2] < (5*T)/10 ) ||
( TS[N] - TS[N-3] < (8*T)/10 ) )
{
next_D = std::max( next_D, std::min( (prev_D*110)/100, (105*avg_D)/100 ) );
}
// Make all insignificant digits zero for easy reading.
i = 1000000000;
while (i > 1) {
if ( next_D > i*100 ) { next_D = ((next_D+i/2)/i)*i; break; }
else { i /= 10; }
}
// Make least 3 digits equal avg of past 10 solvetimes.
if ( next_D > 100000 ) {
next_D = ((next_D+500)/1000)*1000 + std::min(static_cast<uint64_t>(999), (TS[N]-TS[N-10])/10);
}
return next_D;
}
```
Old code for the last option that tells size current hashrate as multiple of what D expected.
```
// Make least 2 digits = size of hash rate change last 11 blocks if it's statistically significant.
// D=2540035 => hash rate 3.5x higher than D expected. Blocks coming 3.5x too fast.
if ( next_D > 10000 ) {
uint64_t est_HR = (10*(11*T+(TS[N]-TS[N-11])/2))/(TS[N]-TS[N-11]+1);
if ( est_HR > 5 && est_HR < 22 ) { est_HR=0; }
est_HR = std::min(static_cast<uint64_t>(99), est_HR);
next_D = ((next_D+50)/100)*100 + est_HR;
}
```
### LWMA-4 (long commented version)
```
// LWMA-4 difficulty algorithm
// Copyright (c) 2017-2018 Zawy, MIT License
// https://github.com/zawy12/difficulty-algorithms/issues/3
// See commented version for explanations & required config file changes. Fix FTL and MTP!
// REMOVE COMMENTS BELOW THIS LINE.
// Bitcoin clones must lower their FTL. See Bitcoin/Zcash code on the page above.
// Cryptonote et al coins must make the following changes:
// BLOCKCHAIN_TIMESTAMP_CHECK_WINDOW = 11;
// DIFFICULTY_WINDOW = 60; // N=45, 60, and 120 for T=600, 120, 60.
// BLOCK_FUTURE_TIME_LIMIT = DIFFICULTY_WINDOW * DIFFICULTY_TARGET / 20;
// Warning Bytecoin/Karbo clones may not have the following, so check TS & CD vectors size=N+1
// DIFFICULTY_BLOCKS_COUNT = DIFFICULTY_WINDOW+1;
// The BLOCKS_COUNT is to make timestamps & cumulative_difficulty vectors size N+1
// CN coins (Monero < 12.3) must deploy the Jagerman MTP Patch. See:
// https://github.com/loki-project/loki/pull/26 or
// https://github.com/graft-project/GraftNetwork/pull/118/files
difficulty_type next_difficulty_v3(std::vector<uint64_t> timestamps,
std::vector<difficulty_type> cumulative_difficulties) {
uint64_t T = DIFFICULTY_TARGET_V2;
uint64_t N = DIFFICULTY_WINDOW_V2; // N=45, 60, and 90 for T=600, 120, 60.
uint64_t L(0), ST(0), next_D, prev_D, avg_D, i;
assert(timestamps.size() == cumulative_difficulties.size() && timestamps.size() <= N+1 );
// If it's a new coin, do startup code. Do not remove in case other coins copy your code.
uint64_t difficulty_guess = 100;
if (timestamps.size() <= 12 ) { return difficulty_guess; }
if ( timestamps.size() < N +1 ) { N = timestamps.size()-1; }
// If hashrate/difficulty ratio after a fork is < 1/3 prior ratio, hardcode D for N+1 blocks after fork.
// difficulty_guess = 100000; // Dev may change. Guess low than anything expected.
// if ( height <= UPGRADE_HEIGHT + 1 + N ) { return difficulty_guess; }
// Recreate timestamps (TS) vector to safely handle out-of-sequence timestamps.
std::vector<uint64_t>TS(N+1);
TS[0] = timestamps[0];
for ( i = 1; i <= N; i++) {
if ( timestamps[i] > TS[i-1] ) { TS[i] = timestamps[i]; }
else { TS[i] = TS[i-1]; }
}
// Calculate numerator of LWMA of STs.
for ( i = 1; i <= N; i++) {
// Option 1. The next "if" & "else if" are optional.
// Temper long solvetime drops if they were preceded by 3 or 6 fast solves.
if ( i > 4 && TS[i]-TS[i-1] > 5*T && TS[i-1] - TS[i-4] < (14*T)/10 ) { ST = 2*T; }
else if ( i > 7 && TS[i]-TS[i-1] > 5*T && TS[i-1] - TS[i-7] < 4*T ) { ST = 2*T; }
else { // Assume normal conditions, so get ST.
// LWMA drops too much from long ST, so limit drops with a 5*T limit
ST = std::min(5*T ,TS[i] - TS[i-1]);
}
L += ST * i ;
}
// Allow L small enough for fast start up, but large enough for protection.
if (L < (N*N*T)/20 ) { L = (N*N*T)/20; }
avg_D = ( cumulative_difficulties[N] - cumulative_difficulties[0] )/ N;
// Do core calculation. Math explanation:
// 97/100 adjustment is to get correct avg ST b/c next_D is thrown ~1% high by each:
// 1) 5*T above, 2) 8% jumps below, & 3) Poisson for low N is a gamma distribution.
// N*N(+1)/(2*L) is just 1/LWMA(STs). avg_D/LWMA(STs) is the estimated
// hashrate (HR). T/LWMA(STs) is a ratio in 0.85 to 1.05 range that corrects
// avg_D to try to make avg ST occur in T.
// Prevent overflow for large D and round-off error for small D .
if (avg_D > 2000000*N*N*T) {
next_D = (avg_D/(200*L))*(N*(N+1)*T*97);
}
else { next_D = (avg_D*N*(N+1)*T*97)/(200*L); }
prev_D = cumulative_difficulties[N] - cumulative_difficulties[N-1] ;
// Option 2.
// Miners' decision to mine during low D is a non-linear function like a reverse
// S-curve (D=x-axis, HR=y). This "if" statement is counter-acting approximate S-curve,
// Jump 10% up to 5% above avg_D if last 1 to 3 ST's are fast. Otherwise, keep next_D
if ( ( TS[N] - TS[N-3] < (8*T)/10 ) ||
( TS[N] - TS[N-2] < (5*T)/10 ) ||
( TS[N] - TS[N-1] < (2*T)/10 ) )
{
next_D = std::max( next_D, std::min( (prev_D*110)/100, (105*avg_D)/100 ) );
}
// Option 3. Convert next_D to 3 significant digits.
// Round-off function: ((next_D+i/2)/i)*i
i = 1000000000;
while (i > 1) {
if ( next_D > i*100 ) { next_D = ((next_D+i/2)/i)*i; break; }
else { i /= 10; }
}
// Make least 3 digits equal avg of past 10 solvetimes.
if ( next_D > 100000 ) {
next_D = ((next_D+500)/1000)*1000 + std::min(static_cast<uint64_t>(999), (TS[N]-TS[N-10])/10);
}
return next_D;
// To show difference.
// next_Target = sumTargets*L*2/0.998/T/(N+1)/N/N; // To show the difference.
}
```
```
// LWMA-3 difficulty algorithm
// Copyright (c) 2017-2018 Zawy, MIT License
// https://github.com/zawy12/difficulty-algorithms/issues/3
// See commented version for required config file changes. Fix your FTL and MTP.
// difficulty_type should be uint64_t
difficulty_type next_difficulty_v3(std::vector<uint64_t> timestamps,
std::vector<difficulty_type> cumulative_difficulties) {
uint64_t T = DIFFICULTY_TARGET_V2;
uint64_t N = DIFFICULTY_WINDOW_V2; // N=45, 60, and 90 for T=600, 120, 60.
uint64_t L(0), ST, sum_3_ST(0), next_D, prev_D, this_timestamp, previous_timestamp;
uint64_t avg_ST(0); // for LWMA-4 (1-block jump rule)
assert(timestamps.size() == cumulative_difficulties.size() &&
timestamps.size() <= N+1 );
// If it's a new coin, do startup code.
// Increase difficulty_guess if it needs to be much higher, but guess lower than lowest guess.
uint64_t difficulty_guess = 100;
if (timestamps.size() <= 10 ) { return difficulty_guess; }
if ( timestamps.size() < N +1 ) { N = timestamps.size()-1; }
// If hashrate/difficulty ratio after a fork is < 1/3 prior ratio, hardcode D for N+1 blocks after fork.
// difficulty_guess = 100; // Dev may change. Guess low.
// if (height <= UPGRADE_HEIGHT + N+1 ) { return difficulty_guess; }
previous_timestamp = timestamps[0];
for ( uint64_t i = 1; i <= N; i++) {
if ( timestamps[i] > previous_timestamp ) {
this_timestamp = timestamps[i];
} else { this_timestamp = previous_timestamp+1; }
ST = std::min(6*T ,this_timestamp - previous_timestamp);
previous_timestamp = this_timestamp;
L += ST * i ;
// remove the following line if you do not want the 3-block jump rule
if ( i > N-3 ) { sum_3_ST += ST; }
}
if (L < N*(N+1)*T/4 ) { L = N*(N+1)*T/4; }
next_D = ((cumulative_difficulties[N] - cumulative_difficulties[0])*T*(N+1)*985)/(1000*2*L);
prev_D = cumulative_difficulties[N] - cumulative_difficulties[N-1];
// remove following lines to remove LWMA-4's 1-block jump rule
if ( prev_D*N*105/100 < (cumulative_difficulties[N] - cumulative_difficulties[0]) ) {
next_D =
// delete the following line if you do not want the "jump rule"
if ( sum_3_ST < (8*T)/10) { next_D = (prev_D*108)/100); }
return next_D;
}
```
## LWMA-3 (commented version)
```
// LWMA-3 difficulty algorithm (commented version)
// Copyright (c) 2017-2018 Zawy, MIT License
// https://github.com/zawy12/difficulty-algorithms/issues/3
// Bitcoin clones must lower their FTL.
// Cryptonote et al coins must make the following changes:
// #define BLOCKCHAIN_TIMESTAMP_CHECK_WINDOW 11
// #define CRYPTONOTE_BLOCK_FUTURE_TIME_LIMIT 3 * DIFFICULTY_TARGET
// #define DIFFICULTY_WINDOW 60 // N=45, 60, and 90 for T=600, 120, 60.
// Bytecoin / Karbo clones may not have the following
// #define DIFFICULTY_BLOCKS_COUNT DIFFICULTY_WINDOW+1
// The BLOCKS_COUNT is to make timestamps & cumulative_difficulty vectors size N+1
// Do not sort timestamps.
// CN coins (Monero < 12.3) must deploy the Jagerman MTP Patch. See:
// https://github.com/loki-project/loki/pull/26 or
// https://github.com/graft-project/GraftNetwork/pull/118/files
// difficulty_type should be uint64_t
difficulty_type next_difficulty(std::vector<std::uint64_t> timestamps,
std::vector<difficulty_type> cumulative_difficulties) {
uint64_t T = DIFFICULTY_TARGET; // target solvetime seconds
uint64_t N = DIFFICULTY_WINDOW; // N=45, 60, and 90 for T=600, 120, 60.
uint64_t L(0), ST, sum_3_ST(0), next_D, prev_D, this_timestamp, previous_timestamp;
// Make sure timestamps & CD vectors are not bigger than they are supposed to be.
assert(timestamps.size() == cumulative_difficulties.size() &&
timestamps.size() <= N+1 );
// If it's a new coin, do startup code.
// Increase difficulty_guess if it needs to be much higher, but guess lower than lowest guess.
uint64_t difficulty_guess = 100;
if (timestamps.size() <= 10 ) { return difficulty_guess; }
// Use "if" instead of "else if" in case vectors are incorrectly N all the time instead of N+1.
if ( timestamps.size() < N +1 ) { N = timestamps.size()-1; }
// If hashrate/difficulty ratio after a fork is < 1/3 prior ratio, hardcode D for N+1 blocks after fork.
// difficulty_guess = 100; // Dev may change. Guess low.
// if (height <= UPGRADE_HEIGHT + N+1 ) { return difficulty_guess; }
// N is most recently solved block.
previous_timestamp = timestamps[0];
for ( uint64_t i = 1; i <= N; i++) {
// prevent out-of-sequence timestamps in a way that prevents
// an exploit caused by "if ST< 0 then ST = 0"
if (timestamps[i] > previous_timestamp ) {
this_timestamp = timestamps[i];
} else { this_timestamp = previous_timestamp+1 ; }
// Limit solvetime ST to 6*T to prevent large drop in difficulty that could cause oscillations.
ST = std::min(6*T ,this_timestamp - previous_timestamp);
previous_timestamp = this_timestamp;
L += ST * i ; // give linearly higher weight to more recent solvetimes
// delete the following line if you do not want the "jump rule"
if ( i > N-3 ) { sum_3_ST += ST; } // used below to check for hashrate jumps
}
// Calculate next_D = avgD * T / LWMA(STs) using integer math
if (L < N*(N+1)*T/4 ) { L = N*(N+1)*T/4; }
next_D = ((cumulative_difficulties[N] - cumulative_difficulties[0])*T*(N+1)*99)/(100*2*L);
prev_D = cumulative_difficulties[N] - cumulative_difficulties[N-1];
// If last 3 solvetimes were so fast it's probably a jump in hashrate, increase D 8%.
// delete the following line if you do not want the "jump rule"
if ( sum_3_ST < (8*T)/10) { next_D = std::max(next_D,(prev_D*108)/100); }
return next_D;
// next_Target = sumTargets*L*2/0.998/T/(N+1)/N/N; // To show the difference.
}
```
// Suggested optional code if hashrate/difficulty ratio after a fork will be < 1/3 prior ratio.
// int64_t fork_height = 30;
// int64_t height = [ global scope height variable ];
// if ( height >= fork_height && height <= fork_height + 6 ) { return difficulty_guess; }
// else if ( height < fork_height + N + 1 ) {
// N = height - fork_height - 1;
// std::reverse(timestamps.begin(), timestamps.end());
// std::reverse(cumulative_difficulties.begin(), cumulative_difficulties.end());
// timestamps.resize() = N+1;
// cumulative_difficulties.resize() = N+1;
// std::reverse(timestamps.begin(), timestamps.end());
// std::reverse(cumulative_difficulties.begin(), cumulative_difficulties.end());
// }
-->
This is LWMA-2 verses LWMA if there is a 10x attack. There's not any difference for smaller attacks. See further below for LWMA compared to other algos.
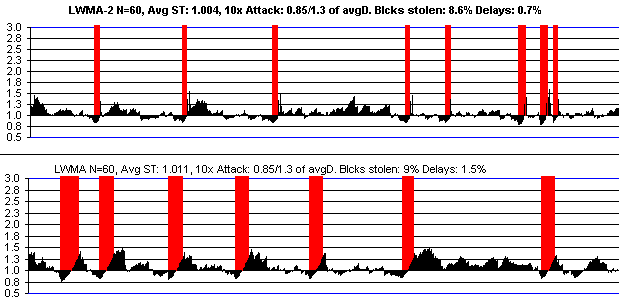
**Credits:**
- dgenr8 for showing LWMA can work
- Aiwe (Karbo) for extensive discussions and motivation.
- Thaer (Masari) for jump-starting LWMA and refinement discussions.
- BTG (h4x4rotab) for finding initial pseudocode error and writing a good clean target method.
- gabetron for pointing out a if ST<0 then ST=0 type of exploit in 1 version before it was used by anyone.
- CDY for pointing out target method was not exact same as difficulty method.
- IPBC and Intense for independently suffering and fixing a sneaky but basic code error.
- Stellite and CDY for independently modifying an idea in my D-LWMA, forking to implement it, and showing me it worked. (The one-sided jump rule). My modification of their idea resulted in LWMA-2.
**Known coins using it**
The names here do not imply endorsement or success or even that they've forked to implement it yet. This is mainly for my reference to check on them later.
Alloy, Balkan, Wownero, Bitcoin Candy, Bitcoin Gold, BitcoiNote, BiteCode, BitCedi, BBScoin, Bitsum, BitcoinZ(?) Brazuk, DigitalNote, Dosh, Dynasty(?), Electronero, Elya, Graft, Haven, IPBC, Ignition, Incognito, Iridium, Intense, Italo, Loki, Karbo, MktCoin, MoneroV, Myztic, MarketCash, Masari, Niobio, NYcoin, Ombre, Parsi, Plura, Qwerty, Redwind?, Saronite, Solace, Stellite, Turtle, UltraNote, Vertical, Zelcash, Zencash. Recent inquiries: Tyche, Dragonglass, TestCoin, Shield 3.0. [update: and many more]
<!--
## Complicated version
## Do not use this version...deprecated
```
// LWMA difficulty algorithm
// Copyright (c) 2017-2018 Zawy, MIT License
// Bitcoin clones with T less than 600 need to change FTL. See instructions.
// Cryptonote coins must make the following changes:
// #define CRYPTONOTE_BLOCK_FUTURE_TIME_LIMIT 400
// #define BLOCKCHAIN_TIMESTAMP_CHECK_WINDOW 11
// #define DIFFICULTY_TARGET 120 // seconds
// #define DIFFICULTY_WINDOW 60
// #define DIFFICULTY_BLOCKS_COUNT DIFFICULTY_WINDOW + 1
// Make sure lag is zero and do not sort timestamps.
// CN coins must also deploy the Jagerman MTP Patch. See:
// https://github.com/loki-project/loki/pull/26#event-1600444609
double T = target_seconds;
double N = DIFFICULTY_WINDOW; // N=60 in all coins.
double FTL = CRYPTONOTE_BLOCK_FUTURE_TIME_LIMIT; // < 3xT
// imestamp and cumulativeDifficulty vectors must be N+1 to get 0 to N elements.
assert (timestamps.size() <= N+1);
assert (cumulative_difficulties.size() == timestamps.size() );
// Return a difficulty of 1 for first 3 blocks if it's the start of the chain.
if (timestamps.size() < 4) { return 1; }
// Otherwise, use a smaller N if the start of the chain is less than N+1.
else if ( timestamps.size() < N+1 ) { N = timestamps.size() - 1; }
// To get an average solvetime to within +/- ~0.1%, use an adjustment factor.
// For N>90, just use adjust = 1.000.
adjust = 0.998;
LWMA=0; harmonic_mean_D = 0;sum_inverse_D = 0;
// avgTarget=0;
// Loop through N most recent blocks to get solvetimes and difficulties.
// You need N+1 most recent timestamps and cumulative_difficulties.
// N = most recently solved block.
for ( int64_t i = 1; i <= N; i++) { // i must be signed
// Solvetime must be a signed integer.
solvetime = timestamp[i] - timestamp[i-1];
// LWMA must be signed.
LWMA += solvetime * i / (N*(N+1)/2);
difficulty = cumulative_difficulties[i] - cumulative_difficulties[i-1]
sum_inverse_D += 1/difficulty;
// If using target instead of difficulty, replace the above with:
// avgTarget += target[i]/N;
}
harmonic_mean_D = N / sum_inverse_D;
return next_difficulty = harmonic_mean_D * T/LWMA * adjust;
// return next_target = avgTarget * LWMA/ T / adjust;
// The harmonic mean of difficulty is possibly an unnecessary complication over the
// arithmetic mean of difficulties. I wanted to make it the exact same as average of targets
// and the solvetime adjustment factor is closer to 1.00, so for some reason it is
// theoretically better (but not noticeably better in practice). The arithmetic mean can be
// calculated without the sum that is inside the loop like this:
// total_work = cumulative_difficulties.back() - cumulative_difficulties.front();
// then replace " harmonic_mean_D" with "total_work/N" in next_difficulty.
// And change the adjust = 0.998 to adjust = 0.9989^(500/N). So the above algorithm
// could be simplified to:
// int64_t LWMA(0), next_difficulty(0);
// for ( int64_t i = 1; i <= N; i++) {
// LWMA += max(-7*T,min(7*t, timestamps[i] - timestamps[i-1])) * i;
// }
// if ( LWMA < T*N ) { LWMA = T*N; }
// next_difficulty = (cumulative_difficulties[N] - cumulative_difficulties[0]) * T * (N+1) / LWMA * adjust / 2
// If someone insists on limits, make them symmetrical and the last step like this 20% limit:
// next_difficulty = max(next_difficulty*0.80,min(next_difficulty/0.80,next_difficulty));
```
-->
**Importance of the averaging window size, N**
The size of of an algorithm's "averaging" window of N blocks is more important than the particular algorithm. Stability comes at a loss in speed of response by making N larger, and vice versa. Being biased towards low N is good because speed is proportional to 1/N while stability is proportional to SQRT(N). In other words, it's easier to get speed from low N than it is to get stability from high N. It appears as if the the top 20 large coins can use an N up to 10x higher (a full day's averaging window) to get a smooth difficulty with no obvious ill-effects. But it's very risky if a coin does not have at least 20% of the dollar reward per hour as the biggest coin for a given POW. Small coins using a large N can look nice and smooth for a month and then go into oscillations from a big miner and end up with 3-day delays between blocks, having to rent hash power to get unstuck. By tracking hashrate more closely, smaller N is more fair to your dedicated miners who are important to marketing. Correctly estimating current hashrate to get the correct block solvetime is the only goal of a difficulty algorithm. This includes the challenge of dealing with bad timestamps. An N too small disastrously attracts on-off mining by varying too much and doesn't track hashrate very well. Large N attracts "transient" miners by not tracking price fast enough and by not penalizing big miners who jump on and off, leaving your dedicated miners with a higher difficulty. This discourages dedicated miners, which causes the difficulty to drop in the next cycle when the big miner jumps on again, leading to worsening oscillations.
<!--
**Timestamp Manipulation**
All fast algorithms (low N) can have the difficulty forced low by >50% hash rate miners who give bad timestamps. This can be reduced by raising N or lowering the nodes' future time limit to FTL = 360 seconds. The amount they can lower difficulty is (N-FTL/T)/N once about every 1.5xFTL. The FTL must be less than one T more than the absolute value of any limit on negative solvetimes like -6xT in order for the negative solvetimes to erase the effect of bad forward timestamps. SMA and Digishield algorithms using a subtraction of the first and last timestamps in the window rather than looking at individual solvetimes like LWMA are subject to the same extent, so they also need a low FTL. Without FTL, they are protected against bad timestamps from < 50% miners because they function the same as allowing negative solvetimes (an honest timestamp that follows a bad timestamp immediately erases the effect of the bad timestamp).
**Why are you allowing negative solvetimes?**
If target solvetime is 100, suppose we get solvetimes of 100, 100, 900, -700, 100, 100. This would indicate the 900 was really 100, as revealed by the -700. If the 900 is fishy it means we're thinking a big miner did not jump off, which we shouldn't assume until we see the 100 after the fact. 900 is > 6xT, so something can be assumed to have happened, either a bad timestamp or miner jumped off. We can't guess it was a bad timestamp until we see the 100. But I want to drop immediately in case 900 was honest. If I do that, the best way to correct it (if the next one indicates it is dishonest) is to just also accept the next one as honest and it will erase the effect of bad timestamp. (Not exactly erase because there is an "area under the curve" I'm not adding back above the curve but I prefer to just get D back to the correct value instead of intentionally raising D higher to get avg solvetime back to perfection.) So I'm being "bipolar" or "unstable" when one of the timestamps is lying (i.e. being unstable themselves), and I'm not making a judgement call (i.e. the timestamps following it could have been unlikely liers). An unstable controller is needed if the system being controlled is unstable. The alternative is to do something like BCH's new algo: we do a median of 3 timestamps on both ends of our subtractions. The 900 is never seen, but it comes at a cost of having a 1 block delay in all blocks. I preferred to assume lies would be less common than the cost of delaying D in all blocks by 1 block. Some have tried ```if ST<0 then ST=0``` to get rid of negative solvetimes. This has resulted in at least 1 coin losing 5000 blocks in 1 hour. The attacker just keeps sending forward timestamp stamps and with the negatives being ignored by the algo while preventing the FTL from being exceeded, the algo just sees long solvetimes and lowers difficulty to "zero". Another option is to do what some LWMA's do ("Neil's method") and subtract current timestamp fro the previous max timestamp. It works but it prevents difficulty from rising as fast back to normal after timestamp manipulation:

**Why are your jumps in LWMA-2 and 3 not symmetrical? Isn't the lack of symmetry dangerous or causing some other problem?**
I have been a big fan of using symmetry like this in the past. I have seen big problems from not using symmetry, like I'm doing. So the asymmetry I'm using was not chosen lightly. I tried many algos with a symmetry for the jumps and the advantages sought were cancelled by the disadvantages. It took BTC Candy and Stellite a long time and live coin results to convince me this asymmetry is the way to go. They implemented modified asymmetrical versions of my symmetrical algorithms. We don't want to attract miners "unjustly"by jumping low ... I mean we want the "long"-term average hashrate (about 6 hour avg) to be reflected in the difficulty, and to "slowly" change....to slowly go up or down (over about 3 hours)......but there is an exception: we want to penalize the sudden heavy mining attack. These jumps have a type of "memoryless-ness" to them ... the difficulty immediately goes back down to the long term average "without prejudice". In other words, the difficulty algo has an immediate forgiveness to the attack so everyone else is not penalized with a higher difficulty after the attacker leaves. I can't think of a specific reason we would want symmetrical "memoryless-ness" drops. There should not be a reason that the network suddenly collapse in hashrate, unless it is an attack that is ending, and that case is being handled correctly with the jumps and forgiveness. LWMA is really good at dropping fast anyway, so much so that the +6xT limit in the loop helps prevent it from dropping too much too fast which was causing a big problem during persistent attacks on certain coins (the attacker seem to be their only miner, so there were long delays which caused a huge drop). If it were symmetrical, it could have oscillations if an attacker finds a favorable on-off pattern. One-sided jumps enables a larger N that "dampens" falls, but does not dampen jumps. The stability is not hardly affected and solvetimes remain exactly correct with this asymmetrical approach.
**Using MTP for bad timestamps**
Digishield / Zcash clones use bitcoin's MTP for protection against bad timestamps. This delays the difficulty response about 6 blocks. It's not protection against > 50% miners because they can "own" the MTP, deciding what the most recent solvetime is. But as explained above, a bad timestamp for < 50% only lowers difficulty for 1 block, and if the FTL is reasonably low, it can't lower it a lot.
-->
**Masari** forked to implement this on December 3, 2017 and [has been performing outstandingly](https://github.com/zawy12/difficulty-algorithms/issues/8).
**Iridium** forked to implement this on January 26, 2018 and [reports success](http://ird.cash/hard-fork-success/). They forked again on March 19, 2018 for other reasons and tweaked it.
**IPBC** forked to implement it March 2, 2018.
**Stellite** implemented it March 9, 2018 to stop bad oscillations.
**Karbowanec** and **QwertyCoin** appear to be about to use it.
## Comparison to other algorithms:
The competing algorithms are LWMA, EMA (exponential moving average), and Digishield. I'll also include SMA (simple moving average) for comparison. This is is the process go through to determine which is best.
First, I set the algorithms' "N" parameter so that they all give the same speed of response to an increase in hash rate (red bars). To give Digishield a fair chance, I removed the 6-block MTP delay. I had to lower its N value from 17 to 13 blocks to make it as fast as the others. I could have raised the other algo's N value instead, but I wanted a faster response than Digishield normally gives (based on watching hash attacks on Zcash and Hush). Also based on those attacks and attacks on other coins, I make my "test attack" below 3x the basline hashrate (red bars) and last for 30 blocks.

Then I simulate real hash attacks starting when difficulty accidentally drops 15% below baseline and end when difficulty is 30% above baseline. I used 3x attacks, but I get the same results for a wide range of attacks. The only clear advantage LWMA and EMA have over Digishield is fewer delays after attacks. The combination of the delay and "blocks stolen" metrics closely follows the result given by a root-mean-square of the error between where difficulty is and where it should be (based on the hash rate). LWMA wins on that metric also for a wide range of hash attack profiles.
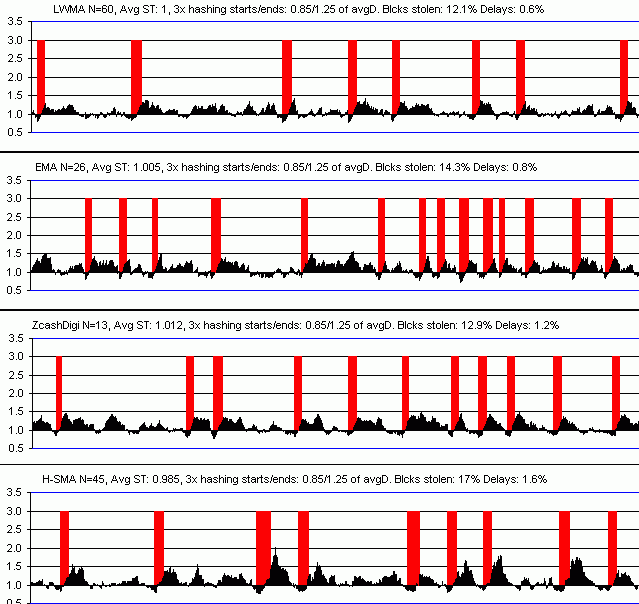
I also consider their stability during constant hash rate.

Here is my spreadsheet for testing algorithms I've spent 9 months devising algorithms, learning from others, and running simulations in it.

Here's Hush with Zcash's Digishield compared to Masari with LWMA. Hush was 10x the market capitalization of Masari when these were done (so it should have been more stable). The beginning of Masari was after it forked to LWMA and attackers were still trying to see if they could profit.

